量子機器學習:註腳內不可不知的四個限制
在機器學習(尤其是深度學習)於過去五年落地應用成功、量子計算也開始噴發地邁向主流後,(起源於2008年的)量子機器學習(Quantum Machine Learning)也開始吸引眾人的目光、火上加火的領域.畢竟其彷彿能用量子物理做到古典機器學習做不到的挑戰,產生動輒就是指數加速的演算法,這好到不可思議的光景這到底多少是泡沫(Hype)、多少是實質(Fact)、又或者在科學傳播中漏掉了許多重要的細節呢?
本篇網誌我要帶大家走過一篇關於量子機器學習的經典回顧文章:『read the fine print』 來探討這理論有嚴苛限制條件這問題(當然包含我個人的解讀分析).此論文於2015年刊登在Nature,作者是量子計算理論大師 Scott Aaronson(對複雜度理論有諸多貢獻、同時提出Boson Sampling這個重要實驗),Scott Aaronson的行文非常通順、內容充滿智慧與幽默、也讓人省思,除了在本文中體現之外也可以參考其大作『Quantum Computing since Democritus』.
前情提要
在量子計算的殺手級應用中,通常人們比較熟知的是:1)破解現行非對稱加密系統的 Shor algorithm 2)加速無結構資料庫搜尋速度的 Grover Algorithm .而在2008年時以三位物理學家為名的HHL algorithm被提出後,人們發現量子電腦「好像」可以指數加速計算反矩陣的速度,接下來就是建立在HHL(反矩陣算法)之上的量子機器學習理論被逐一搬上檯面:包含計算線性回歸、SVM(Support Vector Machine)、PCA(Principal component analysis)等.不過量子機器學習的理論除了受到本文提到的各種藏在註腳內的限制外,更重要的是我們得假設古典演算法的複雜度不變,因為往優化方向移動的古典靶子很有可能讓量子機器學習演算法從指數加速變成多項式加速,後來的事實發展也確實如此.
Scott Aaronson的天才大學專題生(現為PhD )Ewin Tang在2018年石破天驚得提出「受量子計算啟發的」古典演算法,把HHL和基於HHL的演算法指數加速全部降階到多項式加速 … 所以我這篇網誌某方面是在考古,因為HHL 已經被弱化.不過類似的啟示仍舊要放在心上,畢竟量子機器學習仍舊有其他無需HHL演算法的子領域存活:包含量子波茲曼機、量子深度學習(類神經網路)和Hybrid Machine Learning(整合古典和量子機器學習的混合算法).對我來說是真心慶幸自己是做實驗物理,故博士生涯的計畫方向可以改變:從與目標HHL相關的實驗轉向Hybrid Machine Learning相關的實驗,否則就尷尬了.
進入正文解讀註腳
文章在指出HHL 演算法的精妙核心是把「量子波函數給指數化」後便進入正題.請注意以下的反矩陣計算,我們會在說明四個限制時提到他們.
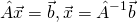
限制一:寫入量子態
這在所有的量子演算法都是必須克服的挑戰,即使N個量子位元可以代表 2^n 個向量的疊加態b,如何把這2^n個數字寫入物理系統是極為巨大的挑戰,如果一個一個寫那當然就不會有指數加速,所以需要特殊的巧門來克服這問題(Shor 和 Grover的初始量子態備置不會遇到這個問題).基本上透過QRAM(量子記憶體,目前還沒有實驗不過已經有架構)把事先準備好的量子態快速下載到量子電腦中,然後把這段量子態備置從複雜度計算中劃掉.重點:QRAM只能應付相當均勻的量子態,如果其中有幾個為度的佔比非常高,那就連QRAM都無法快速製備了…
限制二:能夠有效執行矩陣指數化
解決完入的量子態b,接下來我們就要處理那個反矩陣A.上面已經提過,HHL的奧妙之處波函數量子化,也就是透過A生成e^(-iAt),不過這樣的矩陣其實是有條件限制,他必須要夠稀疏(Sparse):也就是大多數的矩陣單元必須為0,否則這個生成過程如果需要花大量時間,那HHL的指數加速被也會消失.註:至少在無窮維度的量子計算當中,已經有理論提出可以讓任意矩陣指數化,所以這個限制在非傳統的量子計算架構中是可以被忽略的.
限制三:矩陣本徵值
這個矩陣除了要能夠被快速指數化外,他的最大/最小本徵值的比值
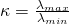
不能隨著矩陣變大而指數增大,否則HHL的加速會被抵消,而這點和「限制二」一樣是必須看具體問題是如何構造矩陣而決定的,非常case-dependent.
限制四:如何讀取答案
當我們通過所有前面的層層關卡,運行完HHL後獲得x之後就高枕無憂了嗎?當然不是,我們獲得的是一個疊加的量子態,如果我們要把這向量的每個數字(每個疊加態的比重)通通透過測量取得,那HHL的加速又會消失(因為我們要測量指數次…),所以到了最後我們只能夠獲得和x相關的統計性質,而不是獲得其細節…結論
Scott Aaronson 在論文中就直接吐槽以上限制,如果哪個資訊科學問題真的都符合以上述四個要求,這麼受限的問題搞不好古典電腦也可以快速解答.尤其是限制一:如果寫入的量子態都是必須相當均勻、不能是有peak的向量(為了QRAM),那搞不好古典的隨機演算法就可以做到類似的技巧,抵銷所謂的量子指數加速(這也確實預言了Ewin Tang 在2018年的「受量子啟發之古典算法」…).
總而言之,如果我們確實想要指數加速的量子演算法,那應該要想辦法構造出一種量子疊加態、其機率分佈是無法輕易透過古典電腦模擬的.也就是必須創造出某種全域數學特徵(global)而非區域性的特徵.到目前為止我們所熟知並使用甚多的數學工具就是量子傅立葉變換,也就是Shor演算法的核心.
補充:因為量子傅立葉變化和其解決的質因數問題是有內在的數學結構,而非完全無結構.所以我認為這個工具絕對不足以讓量子計算機可以解決NP-COMPLETE 的問題(畢竟3SAT連全域結構都沒有),量子計算能夠加速演算都是透過相位干涉消除掉不想要的糾纏態,或許是沒有辦法在本質上攻克NP-COMPLETE了…
原文連結凝視奇點的物理學徒
Like my work? Don't forget to support and clap, let me know that you are with me on the road of creation. Keep this enthusiasm together!