
【技術分享】認識文本分析|Word2Vec, Doc2Vec 比較 (附Python程式碼)
本篇筆記 Python自然語言處理入門的常用方法 Word2Vec,及其延伸:Doc2Vec,表述他們之間的關聯,並以Python實作比較不同方法分辨同樣兩個語句的效果。(介於中間的還有Sent2Vec,概念與Doc2Vec相似)
Word2Vec是什麼?
顧名思義 Word to vector,通過神經網路訓練,將字詞表示成空間中的向量,讓我們可以用向量間的距離,來代表文本語意上的相似程度。這種把字詞向量化的概念即稱為 “embedding”,目的是讓機器理解人類用的詞語,把符號數學化。
那怎麼做到”讓語意相近的字詞向量越靠近”?
Word2Vec主要由兩種神經網絡演算法構成:
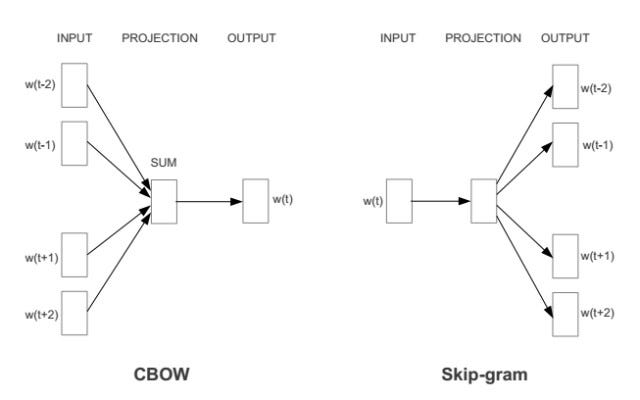
1. CBOW (Continuous Bag of Words):根據上下文關係,預測當前詞語出現的機率。利用所有input data(語料庫)中,每個(經過斷詞後)的上下文詞語組合,預測目標字詞本身出現的機率有多少。圖中的w是每個詞的權重矩陣(訓練完成後會就是該詞的詞向量),CBOW模型的目的是讓當前字詞(要被預測的對象)的出現機率越高越好。
譬如:[‘感冒’, ‘要’, ‘多’, ‘休息’], [‘生病’, ‘要’, ‘多’, ‘休息’]
假設語料庫輸入大多是跟生病休養相關的語句,此時模型就可以判斷上下文關係,學習到 ‘感冒’ 和 ‘生病’ 的語意是相近的,最後算出的cos(餘弦值)也會越大(空間中兩向量越靠近)。
2. Skip-gram:CBOW的相反,根據當前詞語預測上下文詞語的機率。
那Doc2Vec是…
模型能夠判斷單詞間的語意相近程度了,那進一步我們想要知道,詞語組合成的「段落」間的相近程度是如何。
我們有一個選擇,可以將Word2Vec算出的詞向量相加做平均處理,來代表這些詞組成的一段段落的向量;但是這樣就沒有考慮到字詞的先後順序,以及上下文關係,而且段落長度可能相差非常多。
於是Word2Vec論文作者 Tomas Mikolov 再延伸提出了 Doc2Vec方法,比起直接將字詞相加,Doc2Vec考慮字詞先後順序後算出代表一語句段落的向量。
那如何做到讓模型”參考到字詞順序及上下文關係”?
Doc2Vec跟Word2Vec有異曲同工之妙,這兩種神經網絡演算法其實跟Word2Vec很類似:

- PV-DM (Paragraph Vector – Distributed Memory)
跟CBOW很像,只是多了paragraph_id (會先映射成一paragraph vector)。訓練過程中 paragraph_id跟詞一樣保持不變、參與每個詞的訓練,待每個詞都被訓練到以後,也會獲得一個代表這段文檔的向量(文檔權重D)。 - PV-DBOW (Paragraph Vector – Distributed Bag-of-words)
跟Skip-gram很像,使用文檔權重矩陣來預測每個詞出現的機率。
[實作] 2個相同句子,用Word2Vec單詞向量相加 v.s. Doc2Vec.infer_vector ,對相似度判斷的效果
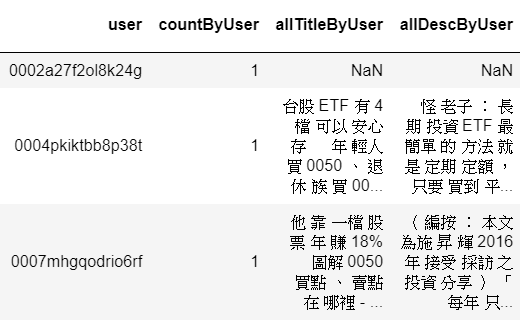
使用商周部分網站文章,涵蓋 良醫健康網、Smart自學網、商周財富網,爬取標題、經jieba斷詞處理,並將同一訪客曾瀏覽過的斷詞紀錄接在一起,產生如左圖的dataframe:(示意)
(1) 引入所需套件及設定:
import nltk
nltk.download('punkt')
from nltk.corpus import stopwords
from nltk.tokenize import sent_tokenize, word_tokenize
from gensim.models import Word2Vec
from gensim.models.doc2vec import Doc2Vec, TaggedDocumentimport numpy as np
import pandas as pd
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all" # 顯示所有output
import warnings
warnings.filterwarnings('ignore')(2) 放入Word2Vec及Doc2Vec模型前 的資料處理:
stopword_list_ch = pd.read_csv('stopwords.csv') #中文停用字
stopword_list_ch = list(stopword_list_ch['$'].values)
manual_stop_list = [',','『 ','\\n','{','}','-','|','(',')',',','˙','..','/','...']
for w in manual_stop_list:
stopword_list_ch.append(w)
# Word2Vec: 將上面的斷詞資料 依空格切割 包成Word2Vec model的input格式
input_w2v = []
for i in range(len(raw_file)):
input_w2v.append(raw_file.allTitleByUser[i].split(' '))# Doc2Vec: TaggedDocument
no_nan_words_file = raw_file.fillna('')
tagged_jieba = [
TaggedDocument(
words=[w for w in word_tokenize(p) if not w in stopword_list_ch], tags=[i]) for i,p in enumerate(no_nan_words_file.allTitleByUser
)
](3) Train 簡易Model:
# Word2Vec
model_w2v = Word2Vec(input_w2v, size=300)
model_w2v.save('test_word2vec.model')
print('W2V model saved!')# Doc2Vec
model_d2v = Doc2Vec(tagged_jieba,
size=20,
alpha=0.025,
min_alpha=0.00025,
min_count=5,
dm=1)
# dm=1 : ‘distributed memory’ (PV-DM) ; dm =0 : ‘distributed bag of words’ (PV-DBOW)model_d2v.train(tagged_jieba,
total_examples=model.corpus_count,
epochs=20)model_d2v.save('test_doc2vec.model')
print('D2V model saved!')(4) 產生範例句段之向量:
# Word2Vec
model_w2v = Word2Vec.load('test_word2vec.model')exp_sent_1 = ['台股', 'ETF', '安心', '存', '年輕人', '買', '0050', '退休族', '買', '0056']
exp_sent_2 = ['投資', '三', '步驟', '小資女', '艾蜜莉', '超', '完整', '解答']vec_sent_1_w2v = np.zeros(300)
vec_sent_2_w2v = np.zeros(300)
for w in exp_sent_1:
vec_sent_1_w2v += model_w2v[w]
print(vec_sent_1_w2v)
for w in exp_sent_2:
vec_sent_2_w2v += model_w2v[w]
print(vec_sent_2_w2v)# Doc2Vec
model_d2v = Doc2Vec.load('test_doc2vec.model')
exp_sent_1_doc = word_tokenize('台股 ETF 安心 存 年輕人 買 0050 退休族 買 0056')
exp_sent_2_doc = word_tokenize('投資 三 步驟 小資女 艾蜜莉 超 完整 解答')
vec_sent_1_d2v = model_d2v.infer_vector(exp_sent_1_doc)
print(vec_sent_1_d2v)
vec_sent_2_d2v = model_d2v.infer_vector(exp_sent_2_doc)
print(vec_sent_2_d2v)(5) 計算Cosine Similarity:量化呈現,向量在空間中的距離有多近?
by 歐式距離可推導出Cos夾角公式,1表完全同向,0表相互獨立,-1表完全不同向。

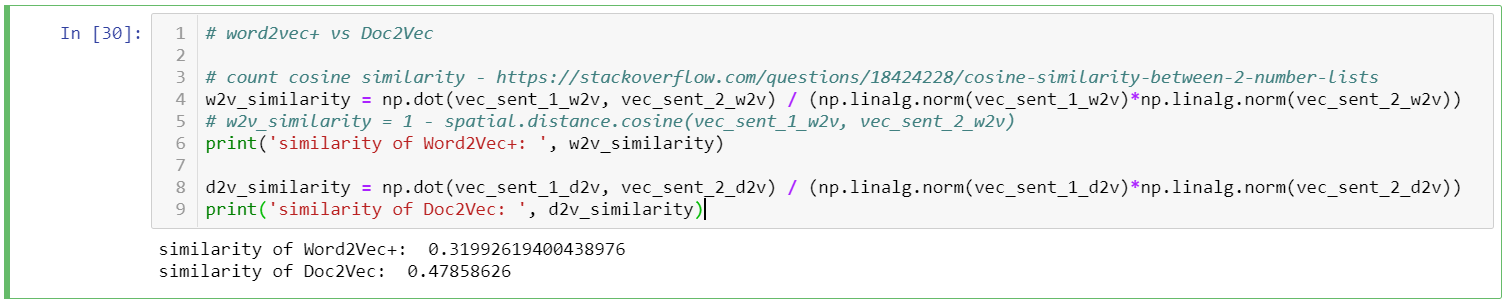
w2v_similarity = np.dot(vec_sent_1_w2v, vec_sent_2_w2v) / (np.linalg.norm(vec_sent_1_w2v)*np.linalg.norm(vec_sent_2_w2v))
print('similarity of Word2Vec+: ', w2v_similarity)d2v_similarity = np.dot(vec_sent_1_d2v, vec_sent_2_d2v) / (np.linalg.norm(vec_sent_1_d2v)*np.linalg.norm(vec_sent_2_d2v))
print('similarity of Doc2Vec: ', d2v_similarity)計算結果:Doc2Vec向量的距離算出兩句之間的相似度比Word2Vec得出結果更高。兩句都是投資相關,若是分類目的,相似度確實越高越好;但因為兩句講述的主題稍有不同(ETF v.s. 艾蜜莉投資教學) ,我們不能說0.47的相似度就是最正確。
反省出更好的測試方式是,可以拿語序相反就有不同意思的句子,應該會更明顯看出兩種word-embedding方法,判斷相似度的差異。
參考資料:
1. 【演算法】word2vec與doc2vec模型:http://www.ipshop.xyz/9903.html
2. 一周論文 | Word2Vec 作者Tomas Mikolov 的三篇代表作:https://kknews.cc/zh-tw/news/69j4am.html
3. 深度学习笔记——Word2vec和Doc2vec原理理解并结合代码分析:https://blog.csdn.net/mpk_no1/article/details/72458003
4. Word2Vec基礎實作參考:以 gensim 訓練中文詞向量http://zake7749.github.io/2016/08/28/word2vec-with-gensim/