
【技術分享】認識文本分析|給我一段話,我告訴你重點在哪:對文本重點字詞加權的TF-IDF方法
適逢上週五2019數位奇點獎,敝公司獲得【最佳數據科技創新獎】銅獎;當中的案件我們使用到tfidf產生的文本向量做KMeans分群。正好想試試再讓文章簡單好懂一點,本周就單純只介紹這個文本分析很常用到的統計方法:TF-IDF。
一句話解釋TF-IDF——用來從一段文字/一個語料庫中,給越重要的字詞/文檔,越高的加權分數。
本篇文章共三段,第一段講述概念與公式,第二段帶一個簡單的script印出一句話的tfidf稀疏矩陣,最後第三段提及TF-IDF的限制和改進。
預計閱讀時間:5–8 mins。
概念解釋
你看,TF – IDF ,前面的TF是Term Frequency的縮寫,後面的IDF是Inverse Document Frequency的縮寫,合在一起則說明了它如何計算出誰是相對比較重要的字詞——字詞的重要性隨著 在文本出現的頻率越高則越高;在不同文本檔案間出現的次數越高則反而降低。
所以聰明的你會猜得到,它由兩個公式組成:
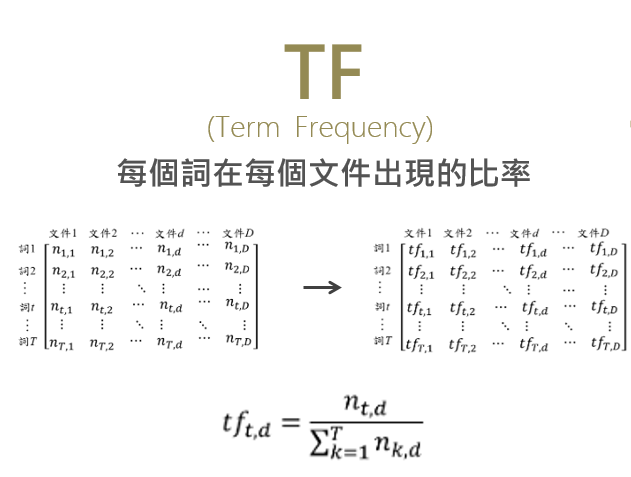
1. TF (Term Frequency) 詞頻
我們先把拆解出來的每個詞在各檔案出現的次數,一一列出,組成矩陣。接著當我們要把這個矩陣中,『詞1』在『文件1』的TF值算出來時,我們是用『詞1在文件1出現的次數』除以『文件1中所有詞出現次數的總和(可說是總字數)』。
如此一來,我們才能在不同長度的文章間比較字詞的出現頻率。
2. IDF (Inverse Document Frequency) 逆向檔案頻率
如果經過第1步的計算,此時我們有兩個詞頻一樣的字詞,還有什麼變數影響他們可能更重要 或 不重要?
如果有一個詞事實上很常出現在不同文章內,那即使該字詞的頻率很高,它是不是不足以代表這篇文章? 拿藝人上電視節目舉例,如果藝人A和藝人B上X視節目的次數相同;但藝人A只上X視節目,藝人B還會出現在X立、X大的節目,對X視節目來說,最具代表性的還是藝人A,而不是有可能在X立、X大上過更多次節目的藝人B。
所以我們這裡再用IDF,計算該詞的「代表性」。
由『文章數總和』除以『該字詞出現過的文章篇數』後,取log值*。實際應用中為了避免分母=0,因此通常分母會是dt+1。

*注:
IDF之所以取log的原因,有過多篇論文討論。把「詞在所有文章出現的篇數」想成「要從這些文章中,隨機抽一篇能夠抽到包含該詞的文章的『機率』有多少」;也就是這個詞在這些文章中被找到的機率分布。
另一個原因是,如果不取log,比方說總數是100000篇文章,如果因為拼錯字導致此詞僅有1篇出現過,TF-IDF最後給這詞的加權會出現太大的值,使得線性加權方式反而表現得沒那麼好。
綜合兩個公式值相乘,便得到我們今天介紹的TF-IDF值:

程式實作
結束前,我們用scikit-learn 提供的CountVectorizer, TfidfTransformer來試著對多個句子產生tfidf值矩陣。(*注意:要經過斷詞處理後再做tfidf)
另外值得一提的是,如果是英文文本實作tfidf,通常還會需要詞型還原 Stemming(譬如:teach / taught,理當視為同義,不可以讓tfidf算成兩種詞),因為有文法時態、單複數的問題。
1. 引入套件
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
import jieba
jieba.set_dictionary('../../zh-TW_dict/dict.txt.big.txt') # 使用官方的繁體詞典2. 再額外設定停用字符
stopword_list_ch = pd.read_csv('../../zh-TW_dict/stopwords.csv')
stopword_list_ch = list(stopword_list_ch['$'].values)
manual_stop_list = [',','.','*',':',';','#','@','!','%','^','&','+','=','~','『 ','\\n','{','}','-','|','(',')',',','˙','..','/','...','$','\r','\n','\t',' ','\r\n','▼','|','【','】','[',']','「','」','★','▎','↘','◤']
for w in manual_stop_list:
stopword_list_ch.append(w)
stopword_list_ch3. 處理文章資料
df_article = pd.read_csv('your_file.csv')jieba_results = []
for sent in df_article.sentences:
w_string = str()
ws = jieba.cut(sent, cut_all=False) # 精確模式
for w in ws:
if w not in stopword_list_ch:
w_string += w + ' '
jieba_results.append(w_string)df_article['sent_jieba'] = jieba_results4. 基本tfidf script
vectorizer = CountVectorizer(stop_words = manual_stop_list)
transformer = TfidfTransformer()
X = vectorizer.fit_transform(df_article.sent_jieba)
tfidf = transformer.fit_transform(X)
weight = tfidf.toarray()5. 檢視結果
print(weight.shape)
print(tfidf[0])
print(weight[0])
這邊我們先拿前5個句子來測試,所以你會看到weight.shape是(5, 39),它是指有5列、39行的矩陣構成;一列就是一個句子,39行是指這5句裡所有出現過的不重複字詞共有39個。矩陣裡的數值就是這39個詞,在這5句中的tfidf值。
*tfidf的output因為是個sparse matrix(稀疏矩陣,未來我們有機會講到),tfidf.toarray() 可轉換成2-dimensional ndarray的形式。
tfidf[0]是指,第1句的tfidf稀疏矩陣,紀錄第幾列、第幾行的非零值是多少。weight[0]則完整印出39個詞在第一句中的tfidf值,0則代表這詞沒出現在第一句。
你可以想像,如果我們對每一句做完tfidf值,這樣的矩陣代表我所有的詞庫中,誰對哪篇文章有加權到;所以如果有兩篇文章的tfidf矩陣非零的位置一樣,則這兩篇加權到的字詞一致,表示這兩篇文章意思可能更相近。
TF-IDF的限制及改進方向
TF-IDF是個相對構成簡單的算法,有一些情境下它會誤判特徵詞的重要度:
- 語料庫中剛好都是同類文章,此時具代表性的字詞反而不被加權。
譬如:都是講行銷的文章一起放到語料庫被訓練,因為幾乎每一篇都提到『數位行銷』,最後結果出來,『數位行銷』的IDF值反而比『客戶』、『用戶』之類的詞更低。若使用TF-IDF方法,要注意語料庫的挑選。 - TF-IDF無法考慮到位置訊息。如果你的情況是 文章標題、文章第一句或文章結尾提到其實代表這個詞更重要,此時用TF-IDF就無法參考到詞在文章中的位置訊息。
針對第一點,網路有文章提出了「TF-IWF」,以及「TF-DFIDFO」兩種改善方法。
TF-IWF 詞語逆頻率加權
TF的部分不變,差別在IWF值算法改成:
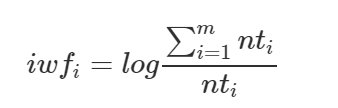
分子:整個語料庫中所有字詞的總頻次(總字詞數)
分母:該字詞在 整個語料庫中 出現的總次數
(簡單說,就是從指參考一篇文章,改成參考整個語料庫(所有文章))
改進優點:
避免當語料庫中有高比例的同類別文章時,重要特徵詞的權重沒有被提升到。
TF-DFIDFO 類別頻率加權
DFI是指「同類別內的分布情況」、DFO則是指「類別間的分布情況」。
改進優點:
增強對”類別”的區分力。
資料來源:
– TF-IDF for document ranking from scratch in Python on real world dataset
– tf-idf 算法中idf为何使用对数?直接用比值或者其他函数不行吗
– TF-IDF模型的概率解释
– TF-IDF之极简化信息论分析
– TF-IDF存在的問題及其改進
– 特征加权之TFIWF
– 改进的TF-IDF中文本特征词加权算法研究
好的,以上就是本周 Python 文本分析的連載。
前段是自己的理解+基本定義、後段限制和改進的部分,是網路資料的回溯歸納。
有問題歡迎留言詢問,看到我會盡力回答的。