[Technology Sharing] Understanding Text Analysis|Word2Vec, Doc2Vec Comparison (with Python code)
In this note, Word2Vec, a common method for getting started with Python natural language processing, and its extension: Doc2Vec, express the relationship between them, and compare the effects of different methods to distinguish the same two statements with Python implementation. (There is also Sent2Vec in the middle, the concept is similar to Doc2Vec)
What is Word2Vec?
As the name implies, Word to vector, through neural network training, represents words as vectors in space, so that we can use the distance between vectors to represent the degree of similarity in text semantics . This concept of vectorizing words is called "embedding", and the purpose is to allow machines to understand human words and mathematicalize symbols.
So how to "make word vectors with similar semantics closer"?
Word2Vec is mainly composed of two neural network algorithms:
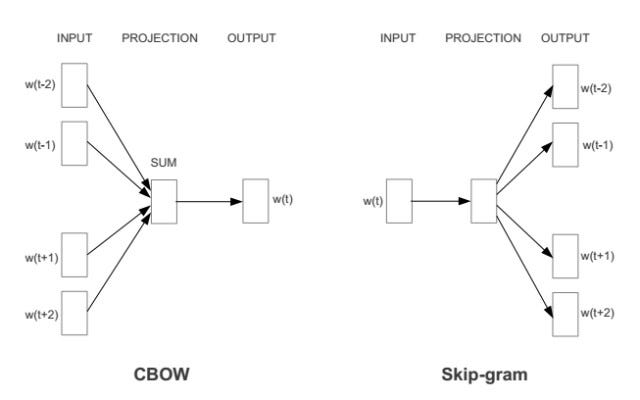
1. CBOW ( Continuous Bag of Words) : Predict the probability of the current word appearing according to the context . Using all the input data (corpus), each context word combination (after word segmentation), predict the probability of the target word itself appearing. The w in the figure is the weight matrix of each word (it will be the word vector of the word after the training is completed). The purpose of the CBOW model is to make the probability of the current word (the object to be predicted) appear as high as possible.
For example: ['cold', 'want', 'more', 'rest'], ['sick', 'want', 'more', 'rest']
Assuming that the corpus input is mostly sentences related to illness and recuperation, then the model can judge the context relationship, learn that the semantics of 'cold' and 'sick' are similar, and the final calculated cos (cosine value) will be larger (space the closer the two vectors are).
2. Skip-gram : The opposite of CBOW, the probability of predicting the context word based on the current word .
That Doc2Vec is...
The model can judge the semantic similarity between words, and then we want to know how similar the "paragraphs" composed of words are.
We have an option to average the word vectors calculated by Word2Vec to represent the vector of a paragraph composed of these words; but this does not take into account the order of words and context, and the length of paragraphs may vary Much.
So Tomas Mikolov, the author of the Word2Vec paper, further proposed the Doc2Vec method. Compared with adding words directly, Doc2Vec calculates a vector representing a sentence paragraph after considering the sequence of words.
How to make the model "reference word order and context"?
Doc2Vec is similar to Word2Vec. These two neural network algorithms are actually very similar to Word2Vec:

- PV-DM (Paragraph Vector – Distributed Memory)
Similar to CBOW, but with an extra paragraph_id (which will be mapped to a paragraph vector first). During the training process, the paragraph_id remains the same as the word, and participates in the training of each word. After each word is trained, a vector representing the document (document weight D) will also be obtained. - PV-DBOW (Paragraph Vector – Distributed Bag-of-words)
Much like Skip-gram, the document weight matrix is used to predict the probability of each word.
[Implementation] 2 identical sentences, add Word2Vec word vector vs Doc2Vec.infer_vector, the effect on similarity judgment
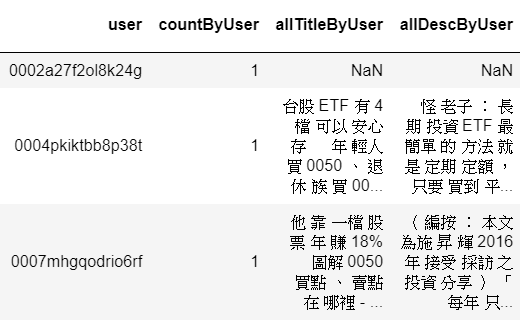
Use some website articles of Shangzhou, covering Liangyi Health Network , Smart Self-learning Network , and Shangzhou Fortune Network , crawl the title, process the word segmentation by jieba, and connect the word segmentation records that the same visitor has browsed together, resulting in the output as shown on the left. The dataframe of the graph: (schematic)
(1) Import required packages and settings:
import nltk nltk.download('punkt') from nltk.corpus import stopwords from nltk.tokenize import sent_tokenize, word_tokenize from gensim.models import Word2Vec from gensim.models.doc2vec import Doc2Vec, TaggedDocumentimport numpy as np import pandas as pd from IPython.core.interactiveshell import InteractiveShell InteractiveShell.ast_node_interactivity = "all" # 顯示所有output import warnings warnings.filterwarnings('ignore')(2) Data processing before putting into Word2Vec and Doc2Vec models:
stopword_list_ch = pd.read_csv('stopwords.csv') #中文停用字stopword_list_ch = list(stopword_list_ch['$'].values) manual_stop_list = [',','『 ','\\n','{','}','-','|','(',')',',','˙','..','/','...'] for w in manual_stop_list: stopword_list_ch.append(w) # Word2Vec: 將上面的斷詞資料依空格切割包成Word2Vec model的input格式input_w2v = [] for i in range(len(raw_file)): input_w2v.append(raw_file.allTitleByUser[i].split(' '))# Doc2Vec: TaggedDocument no_nan_words_file = raw_file.fillna('') tagged_jieba = [ TaggedDocument( words=[w for w in word_tokenize(p) if not w in stopword_list_ch], tags=[i]) for i,p in enumerate(no_nan_words_file.allTitleByUser ) ](3) Train Simple Model:
# Word2Vec model_w2v = Word2Vec(input_w2v, size=300) model_w2v.save('test_word2vec.model') print('W2V model saved!')# Doc2Vec model_d2v = Doc2Vec(tagged_jieba, size=20, alpha=0.025, min_alpha=0.00025, min_count=5, dm=1) # dm=1 : 'distributed memory' (PV-DM) ; dm =0 : 'distributed bag of words' (PV-DBOW)model_d2v.train(tagged_jieba, total_examples=model.corpus_count, epochs=20)model_d2v.save('test_doc2vec.model') print('D2V model saved!')(4) Generate a vector of example sentences:
# Word2Vec model_w2v = Word2Vec.load('test_word2vec.model')exp_sent_1 = ['台股', 'ETF', '安心', '存', '年輕人', '買', '0050', '退休族', '買', '0056'] exp_sent_2 = ['投資', '三', '步驟', '小資女', '艾蜜莉', '超', '完整', '解答']vec_sent_1_w2v = np.zeros(300) vec_sent_2_w2v = np.zeros(300) for w in exp_sent_1: vec_sent_1_w2v += model_w2v[w] print(vec_sent_1_w2v) for w in exp_sent_2: vec_sent_2_w2v += model_w2v[w] print(vec_sent_2_w2v)# Doc2Vec model_d2v = Doc2Vec.load('test_doc2vec.model') exp_sent_1_doc = word_tokenize('台股ETF 安心存年輕人買0050 退休族買0056') exp_sent_2_doc = word_tokenize('投資三步驟小資女艾蜜莉超完整解答') vec_sent_1_d2v = model_d2v.infer_vector(exp_sent_1_doc) print(vec_sent_1_d2v) vec_sent_2_d2v = model_d2v.infer_vector(exp_sent_2_doc) print(vec_sent_2_d2v) (5) Calculate Cosine Similarity: Quantitative presentation, how close is the vector in space?
By Euclidean distance can deduce the Cos angle formula, 1 means completely in the same direction, 0 means independent of each other, -1 means completely different direction.

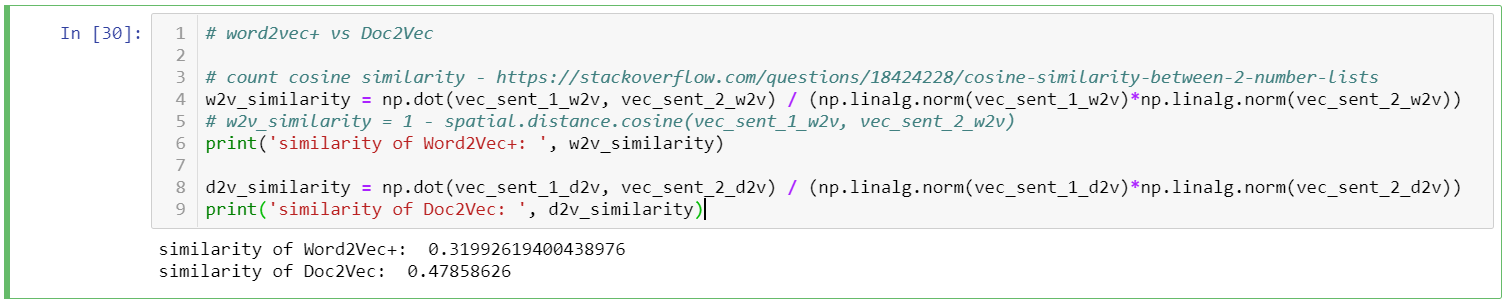
w2v_similarity = np.dot(vec_sent_1_w2v, vec_sent_2_w2v) / (np.linalg.norm(vec_sent_1_w2v)*np.linalg.norm(vec_sent_2_w2v)) print('similarity of Word2Vec+: ', w2v_similarity)d2v_similarity = np.dot(vec_sent_1_d2v, vec_sent_2_d2v) / (np.linalg.norm(vec_sent_1_d2v)*np.linalg.norm(vec_sent_2_d2v)) print('similarity of Doc2Vec: ', d2v_similarity)Calculation result: The similarity between the two sentences calculated by the distance of the Doc2Vec vector is higher than the result obtained by Word2Vec. Both sentences are investment-related, and for classification purposes, the higher the similarity, the better ; but because the two sentences describe slightly different topics (ETF vs Emily's investment teaching), we cannot say that a similarity of 0.47 is the most correct.
Reflecting on a better test method, you can take sentences with different meanings in the opposite word order, and it should be more obvious to see the difference between the two word-embedding methods to judge the difference in similarity.
References:
1. [Algorithm] word2vec and doc2vec models: http://www.ipshop.xyz/9903.html
2. One Week Paper | Three representative works by Word2Vec author Tomas Mikolov: https://kknews.cc/zh-tw/news/69j4am.html
3. Deep learning notes - Word2vec and Doc2vec principles to understand and combine code analysis: https://blog.csdn.net/mpk_no1/article/details/72458003
4. Word2Vec basic implementation reference: training Chinese word vectors with gensimhttp: //zake7749.github.io/2016/08/28/word2vec-with-gensim/
Like my work? Don't forget to support and clap, let me know that you are with me on the road of creation. Keep this enthusiasm together!

- Author
- More